|
Han Yan (严涵) I am a third-year Ph.D. student at Shanghai Jiao Tong University (SJTU), advised by Prof. Chao Ma. I received my bachelor's degree from Artificial Intelligence Honor Class at SJTU in 2023, supervised by Prof. Chao Ma. I am a research intern at Vertex Lab, working with Pan Ji. I was a research intern at Tencent XR Vision Lab, working with Yang Li and Pan Ji. I was a research intern at Bytedance, working with Celong Liu and Xing Mei. I am interested in video generation and 3D computer vision and graphics. |

|
News
|
Publications |
|
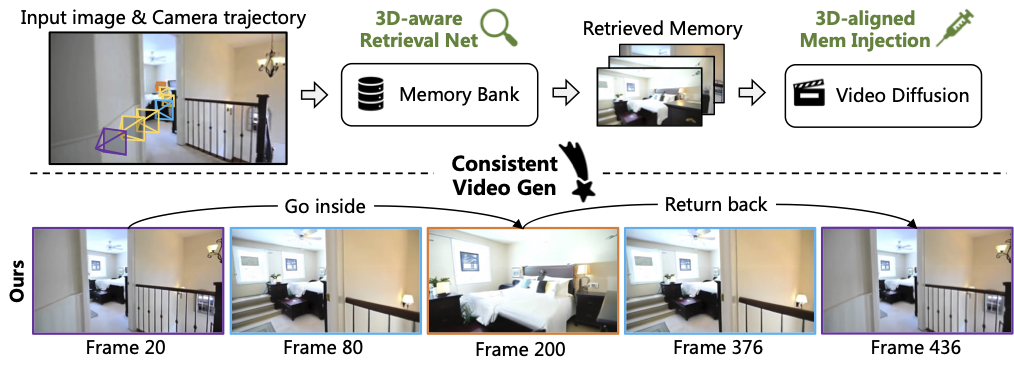
I3DM: Implicit 3D-aware Memory Retrieval and Injection for Consistent Video Scene Generation
Jia Li, Han Yan, Yihang Chen, Siqi Li, Xibin Song, Yifu Wang, Jianfei Cai, Tien-Tsin Wong, Pan Ji arXiv, 2026 project page / arXiv I3DM enables consistent scene exploration via a 3D-aware memory retrieval network and a 3D-aligned memory injection module. |

|
BachVid: Training-Free Video Generation with Consistent Background and Character
Han Yan, Xibin Song, Yifu Wang, Hongdong Li, Pan Ji, Chao Ma arXiv, 2025 project page / arXiv BachVid generates a batch of videos with consistent background and character using a training-free method. |

|
BAG: Body-Aligned 3D Wearable Asset Generation
Zhongjin Luo, Yang Li, Mingrui Zhang, Senbo Wang, Han Yan, Xibin Song, Taizhang Shang, Wei Mao, Hongdong Li, Xiaoguang Han, Pan Ji TVCG, 2026 project page / arXiv / video BAG generates 3D wearable asset that can be automatically dressed on given 3D human bodies. |

|
PhyCAGE: Physically Plausible Compositional 3D Asset Generation from a Single Image
Han Yan, Mingrui Zhang, Yang Li, Chao Ma, Pan Ji arXiv, 2024 project page / arXiv / video PhyCAGE generates physically plausible compositional 3D assets from a single image. |

|
Frankenstein: Generating Semantic-Compositional 3D Scenes in One Tri-Plane
Han Yan, Yang Li, Zhennan Wu, Shenzhou Chen, Weixuan Sun, Taizhang Shang, Weizhe Liu, Tian Chen, Xiaqiang Dai, Chao Ma, Hongdong Li, Pan Ji SIGGRAPH Asia, 2024 project page / arXiv / video / code Frankenstein generates semantic-compositional 3D scenes in a single forward pass. |

|
NeuSDFusion: A Spatial-Aware Generative Model for 3D Shape Completion, Reconstruction, and Generation
Ruikai Cui, Weizhe Liu, Weixuan Sun, Senbo Wang, Taizhang Shang, Yang Li, Xibin Song, Han Yan, Zhennan Wu, Shenzhou Chen, Hongdong Li, Pan Ji ECCV, 2024 project page / arXiv NeuSDFusion is a novel spatial-aware 3D shape generation framework. |

|
Blockfusion: Expandable 3D Scene Generation using Latent Tri-plane Extrapolation
Zhennan Wu, Yang Li, Han Yan, Taizhang Shang, Weixuan Sun, Senbo Wang, Ruikai Cui, Weizhe Liu, Hiroyuki Sato, Hongdong Li, and Pan Ji ACM Transaction on Graphics (SIGGRAPH), 2024 project page / arXiv / video / code Blockfusion directly generate large unbounded 3D scene. |

|
PlenVDB: Memory Efficient VDB-Based Radiance Fields for Fast Training and Rendering
Han Yan, Celong Liu, Chao Ma, Xing Mei CVPR, 2023 project page / pdf / video / code PlenVDB directly learns the VDB data to achieve NeRF acceleration. |
Selected Awards
|
Services
|
Miscellanea
|
|
Thanks to Jon Barron for the template, and to Yiheng Pi for taking my profile photo. |